The interviewer will cover 2-4 technical questions covering various topics relating to data science and Big data. This includes both abstract questions about mathematical concepts and problem solving/initiative, as well as experimental design and model building, and MapReduce.
Credit Risk Related
Suppose you were given two years of transaction history. What features would you use to predict credit risk?
- Transaction amount,
- Transaction count,
- Transaction frequency,
- transaction category: bar, grocery, jwery etc.
- transaction channels: credit card, debit card, international wire transfer etc.
- distance between transaction address and mailing address,
- fraud/ risk score.
Are false positives or false negatives more important?
False negative. The cost of false positive is just inspections and some calls to check with customer, but the cost of false negative will be thousands of dollars.
How would you build a model to predict credit card fraud? What are potential Issues.
Inputs & Outputs.: We will map the inputs to the output - in this case zero or one, or the probabilities of credit card fraud. If given years of transactions, the inputs can be the ones in Q1. If given payment information, the inputs can be:
- Past due: 0-30 days, 30-60 days, over 90 days. Number of occurance.
- Credit usage. Debt ratio.
- Monthly income.
- Age. Number of dependents.
Feature Engineering.: Deal with outliers, impute missing data.
Model for imbalanced data.: reference
- Data level: We can either oversample/ undersample,
- Algorithm level: bagging based, or boosting based.or use tree ensembling methods.
Model metrics.: to maximize true positive rate and to minimize false negative rate. If we use accuracy, we might come across accuracy paradox.

Model interpretation.: Oversample the fraud data or undersample the non-fraud data, and then apply decision tree and logistics regression.
ML Questions
How do you handle missing or bad data?
For Missing Data:
- Dropping rows
- Impute data, average, mediean (more robust for high magnitude), most frequent value
- Build model to predict if there is high correlation exists.
For Data with Outliers:
1234567891011121314151617181920212223242526272829303132333435363738394041424344'''Code reference:https://github.com/IdoZehori/Credit-Score/blob/master/Credit%20score.ipynb'''def mad_based_outlier(points, thresh=3.5):if len(points.shape) == 1:points = points[:,None]median = np.median(points, axis=0)diff = np.sum((points - median)**2, axis=-1)diff = np.sqrt(diff)med_abs_deviation = np.median(diff)modified_z_score = 0.6745 * diff / med_abs_deviationreturn modified_z_score > threshdef percentile_based_outlier(data, threshold=95):diff = (100 - threshold) / 2.0(minval, maxval) = np.percentile(data, [diff, 100 - diff])return ((data < minval) | (data > maxval))def std_div(data, threshold=3):std = data.std()mean = data.mean()isOutlier = []for val in data:if val/std > threshold:isOutlier.append(True)else:isOutlier.append(False)return isOutlierdef outlierVote(data):x = percentile_based_outlier(data)y = mad_based_outlier(data)z = std_div(data)temp = zip(data.index, x, y, z)final = []for i in range(len(temp)):if temp[i].count(False) >= 2:final.append(False)else:final.append(True)return final
How would you use existing features to add new features?
- Transfer learning
- Transaction frequency, amount sum, times
If you’re attempting to predict a customer’s gender, and you only have 100 data points, what problems could arise?
Overfitting. We might learn too much into some particular patterns within this small sample set so we lose generalization abilities on other datasets.
Explain the bias-variance tradeoff. Reference
We call a model high bias if it’s robust to dataset, but it’s too simple so it can’t really get the prediction right. We call a model high variance if it can get things right but it’s too complicated so it’s super specific to datasets so lose the generalization ability to other datasets. Somewhere in the middle of too simple and too complicated we can find the right model, but going along one way or another will increase either bias or variance while decrease another one.
What does regularization do?
Regularization penalizes complex models. It prevents the model from overfitting.
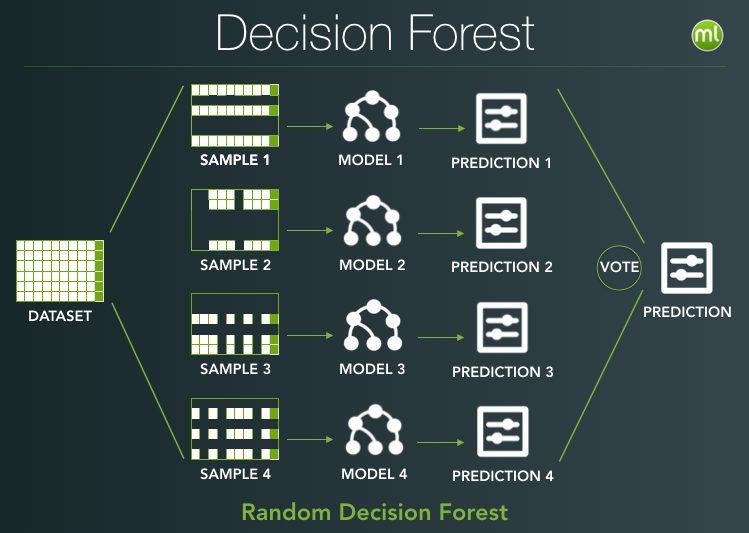
Difference between random forest and gradient boosted tree.
Bagging and boosting are both ensemble methods to turn weak classifiers into a strong one.
Bagging: to train a bunch of same weak learners from a subset of training data, and then take majority votes. The subset is taken using bootstrap method (sampling with replacement), and could be a subset of all training examples or a subset of all features.
Boosting: to train a bunch of different weak learners from the whole set of training data. The whole idea is to iteratively add weights to examples that were wrongly classified by previous classifier combinations.
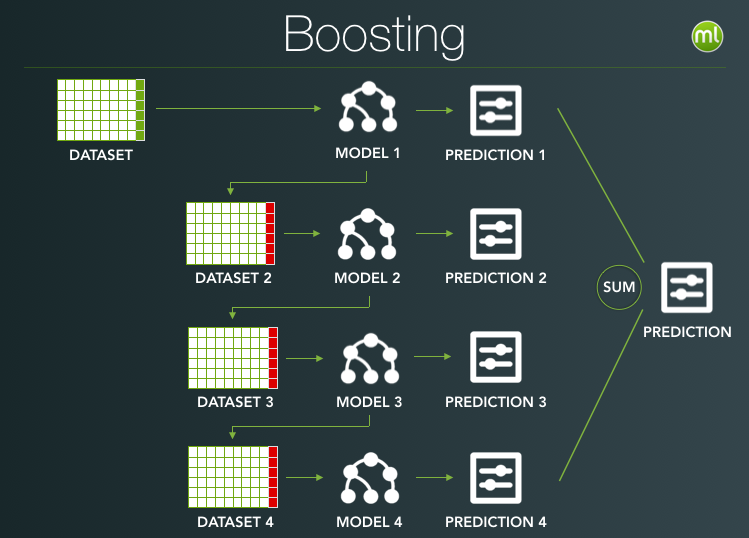 the above two images are from The Down Low on Boosting
the above two images are from The Down Low on Boosting
Design an AI program for Tic-tac-toe
https://en.wikipedia.org/wiki/Tic-tac-toe
Statistics
- Interpret this ANOVA table.
What is VIF (in regression output)?
It is a measure of how much the variance of the estimated regression coefficient bk is “inflated” by the existence of correlation among the predictor variables in the model. A VIF of 1 means that there is no correlation among the kth predictor and the remaining predictor variables, and hence the variance of bk is not inflated at all. The general rule of thumb is that VIFs exceeding 4 warrant further investigation, while VIFs exceeding 10 are signs of serious multicollinearity requiring correction. Reference
Engineering
Write pseudocode for map reduce
123456789101112map(String key, String value)// key: document name// value: document contentsfor each word w in valueEmitIntermediate(w, "1")reduce(String key, Iterator values):// key: word// values: a list of countsfor each v in values:result += ParseInt(v);Emit(AsString(result));
1234567891011121314151617181920212223public class WordCount {public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());output.collect(word, one);}}}public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {int sum = 0;while (values.hasNext()) {sum += values.next().get();}output.collect(key, new IntWritable(sum));}}
##Behavioral/ Project Walkthrough
- Describe a time you worked on a team.
- How do you learn something new?
- Tell me about your experience in neural network?
- Tell me about a time that you had to persuade somebody